Mỗi tháng trả $22–$330 cho ElevenLabs để clone giọng và lồng tiếng video — nghe có vẻ bình thường nếu đó là công việc kiếm tiền. Nhưng nếu bạn chỉ cần làm content, thử nghiệm, hay xây pipeline AI cá nhân, cái giá đó thật ra không cần thiết.
OmniVoice Studio là ứng dụng desktop mã nguồn mở làm được gần như mọi thứ ElevenLabs làm — clone giọng, lồng tiếng video, thiết kế giọng nói, gõ bằng miệng — nhưng chạy 100% trên máy bạn, không cần tài khoản, không cần API key, không gửi dữ liệu lên cloud. Dự án hiện có hơn 3.600 sao trên GitHub và đang phát triển khá nhanh.
Lưu ý trước khi dùng: OmniVoice Studio hiện đang ở giai đoạn beta, tức là có thể gặp lỗi giữa các phiên bản. Nếu muốn ổn định hơn, tác giả khuyến khích clone repo về và chạy từ source thay vì dùng bản cài sẵn.
Tại sao lại so sánh OmniVoice Studio với ElevenLabs?
ElevenLabs là dịch vụ clone giọng và tổng hợp tiếng phổ biến nhất hiện tại, nhưng có vài điểm hạn chế rõ ràng:
- Chi phí: gói rẻ nhất $5/tháng, gói dùng nghiêm túc từ $22 trở lên, lên đến $330/tháng
- Dữ liệu âm thanh được xử lý trên server của họ — với nội dung nhạy cảm hoặc giọng cá nhân, đây là vấn đề
- Chỉ hỗ trợ 32 ngôn ngữ
- Không có ứng dụng desktop
OmniVoice Studio giải quyết cả bốn điểm này. Đáng chú ý nhất là con số 646 ngôn ngữ — gấp 20 lần ElevenLabs, và tiếng Việt nằm trong danh sách đó.
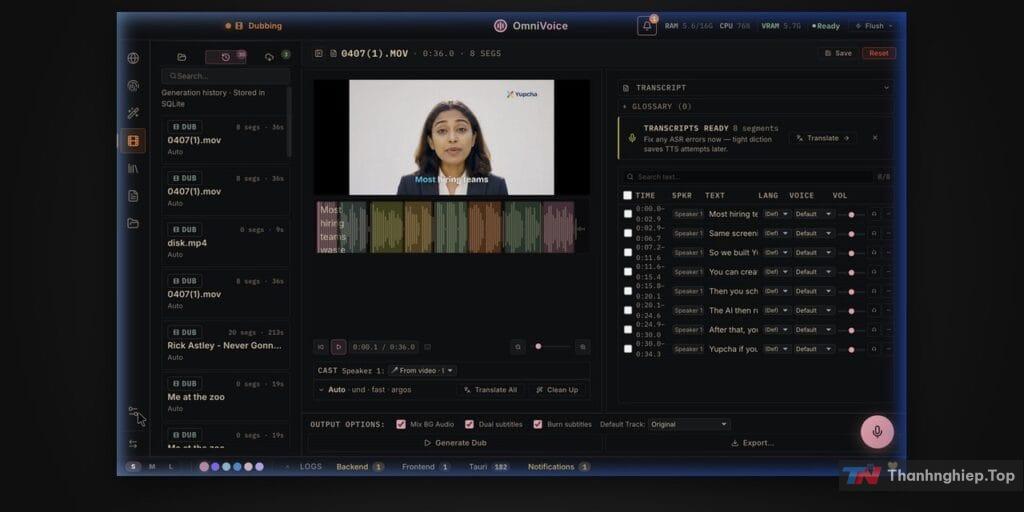
OmniVoice Studio làm được những gì?
Clone giọng chỉ cần 3 giây audio
Tính năng cốt lõi. Bạn chỉ cần một đoạn âm thanh ngắn — đủ 3 giây — là OmniVoice Studio có thể nhái lại giọng đó và tổng hợp bất kỳ văn bản nào bằng giọng ấy, trên 646 ngôn ngữ. Kỹ thuật này gọi là zero-shot voice cloning, không cần train lại mô hình.
Lồng tiếng video đầu cuối
Đây là tính năng mà content creator sẽ thích nhất. Bạn dán link YouTube hoặc upload file video → phần mềm tự nhận dạng lời thoại (WhisperX) → dịch sang ngôn ngữ đích → lồng tiếng bằng giọng đã clone → xuất ra file MP4 hoàn chỉnh. Toàn bộ pipeline chạy cục bộ local.
Thiết kế giọng nói từ đầu
Không có sẵn giọng muốn clone? Bạn có thể tự “chế” một giọng mới bằng cách điều chỉnh từng thông số: giới tính, độ tuổi, giọng vùng, cao độ, tốc độ nói, cảm xúc, phương ngữ. Kéo thanh trượt đến đâu, nghe kết quả đến đó.
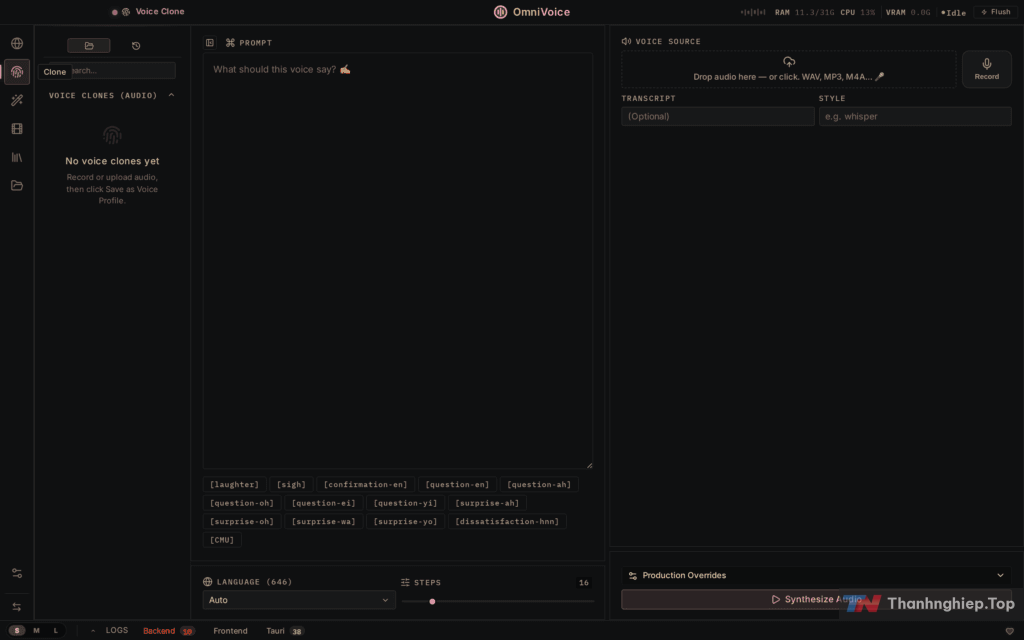
Dictation Widget — gõ bằng cách nói từ bất kỳ đâu
Nhấn ⌘+⇧+Space (macOS) từ bất kỳ ứng dụng nào, nói, rồi văn bản tự xuất hiện tại vị trí con trỏ. Widget hiện lên rồi biến mất, không làm phiền luồng làm việc. Tính năng này hữu ích hơn nhiều so với nghe, vì nó nhận dạng theo thời gian thực và tự paste.
Tách giọng khỏi nhạc nền
Dùng Demucs của Meta để tách phần giọng người ra khỏi nhạc nền. Phần nhạc nền vẫn được giữ nguyên, chỉ giọng người được xử lý riêng. Hữu ích khi bạn muốn thay giọng đọc trong một video có nhạc nền.
Nhận diện người nói trong file âm thanh
Speaker Diarization — phần mềm tự phân tích file âm thanh nhiều người nói và gắn nhãn “ai nói đoạn nào”. Dùng Pyannote kết hợp WhisperX. Tiện cho podcast, phỏng vấn, hay bất kỳ nội dung nhiều giọng.
Xử lý hàng loạt
Thả 50 video vào hàng chờ, đặt thông số, để máy chạy. Batch Queue theo dõi tiến độ từng file và xuất kết quả khi xong. Phù hợp khi cần dub video sang nhiều ngôn ngữ cùng lúc.
Tích hợp MCP — dùng từ Claude Code hay Cursor
OmniVoice Studio đi kèm server MCP tích hợp sẵn. Nghĩa là bạn có thể gọi các tính năng lồng tiếng, clone giọng từ bên trong Claude Code, Cursor hay bất kỳ công cụ nào hỗ trợ MCP — không cần mở giao diện đồ họa.
Watermark ẩn chống deepfake
Dùng AudioSeal của Meta để nhúng watermark vô hình vào mọi file âm thanh AI tạo ra. Watermark này tồn tại ngay cả sau khi nén file, và có thể phát hiện bằng API riêng. Đây là tính năng AI provenance — chứng minh file được tạo bởi AI.
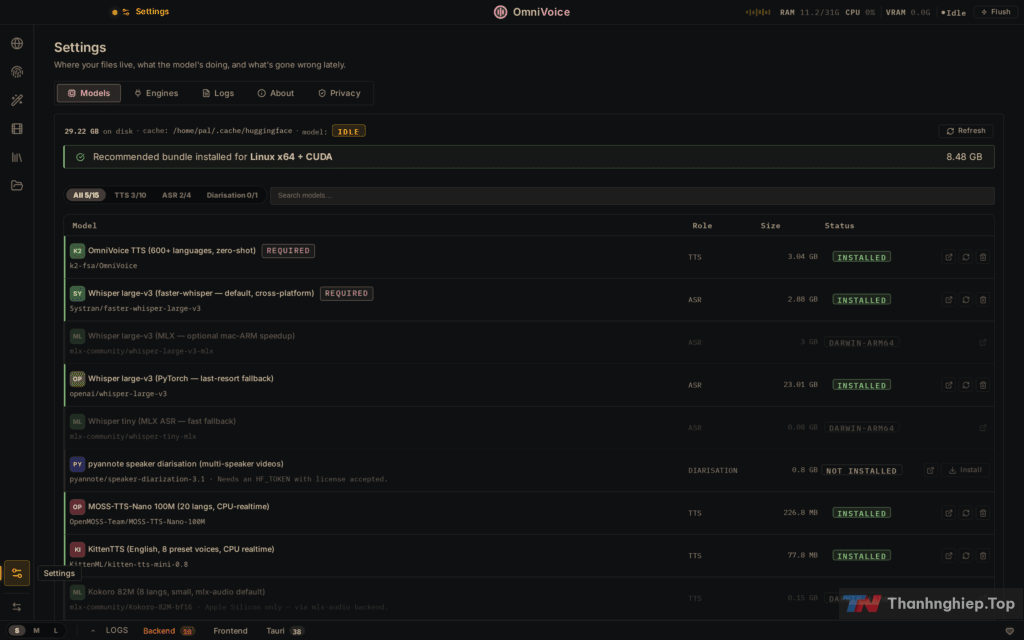
Cấu hình máy cần có
| Tối thiểu | Khuyến nghị | |
|---|---|---|
| RAM | 8 GB | 16 GB+ |
| VRAM (GPU) | 4 GB | 8 GB+ (NVIDIA RTX 3060+) |
| Ổ đĩa | 10 GB trống | 20 GB+ SSD |
| Python | 3.10+ | 3.11–3.12 |
| GPU | Không bắt buộc | NVIDIA CUDA / Apple Silicon / AMD ROCm |
Không có GPU vẫn chạy được bằng CPU, chỉ chậm hơn khoảng 3 lần. Nếu VRAM dưới 8 GB, phần mềm tự động chuyển TTS sang CPU trong lúc transcribe — không cần cấu hình gì thêm.
6 engine tổng hợp giọng để chọn
| Engine | Ngôn ngữ | Clone giọng | macOS Apple Silicon | Windows / Linux |
|---|---|---|---|---|
| OmniVoice (mặc định) | 600+ | ✅ | ✅ MPS | ✅ CUDA/CPU |
| CosyVoice 3 | 9 + 18 phương ngữ | ✅ | ✅ MPS | ✅ CUDA/CPU |
| MLX-Audio | Đa ngôn ngữ | Tùy | ✅ Native | ❌ |
| VoxCPM2 | 30 | ✅ | ✅ MPS | ✅ CUDA/CPU |
| MOSS-TTS-Nano | 20 | ✅ | ✅ CPU | ✅ CUDA/CPU |
| KittenTTS | Tiếng Anh | ❌ | ✅ CPU | ✅ CPU |
Engine mặc định (OmniVoice) là lựa chọn tốt nhất cho đa ngôn ngữ. MLX-Audio chỉ chạy trên Apple Silicon nhưng rất nhanh nhờ tối ưu cho chip M-series.
Giấy phép và điều khoản dùng thương mại
Đây là điểm quan trọng cần đọc kỹ trước khi dùng cho công việc.
OmniVoice Studio dùng giấy phép FSL-1.1-ALv2 — không phải giấy phép mã nguồn mở hoàn toàn theo nghĩa truyền thống. Cụ thể:
- Miễn phí cho cá nhân, học tập, nghiên cứu, nội bộ nhóm, phi thương mại
- Cần mua license thương mại nếu bạn xây dựng sản phẩm hoặc dịch vụ cạnh tranh trực tiếp với OmniVoice Studio
- Mỗi phiên bản tự động chuyển sang Apache 2.0 sau 2 năm kể từ ngày phát hành
Với creator làm content cá nhân hoặc dùng nội bộ, không có gì phải lo cả.
Tải về và cài đặt OmniVoice Studio
Tải bản cài sẵn mới nhất tại trang GitHub:
👉 github.com/debpalash/OmniVoice-Studio
Hỗ trợ macOS (DMG), Windows (MSI), Linux (AppImage và .deb). Hướng dẫn cài cho từng hệ điều hành có trong thư mục docs/install/ của repo.
Mẹo nhỏ: Nếu muốn có tính năng mới nhất và ít gặp lỗi hơn, clone repo về và chạy từ source thay vì dùng bản cài sẵn — đây là khuyến nghị của chính tác giả.
Nếu bạn đang trả tiền subscription hàng tháng chỉ để lồng tiếng vài video hay thử nghiệm clone giọng, OmniVoice Studio đáng để bỏ vài tiếng cài thử. Chạy cục bộ local, không lo dữ liệu bị gửi đi đâu, và miễn phí cho hầu hết trường hợp cá nhân. Thử xem có phù hợp không rồi tính tiếp.
Bạn đã thử công cụ AI tổng hợp giọng nào khác chạy local chưa? Chia sẻ bên dưới nhé!





Để lại một bình luận